







- 【喜訊】華頡科技成功通過2025年創新型中小企業評價 2025-07-31
- 如何延長工控機使用壽命?關鍵維護策略與注意事項 2025-07-16
- 市場上的工控機改如何選擇?接口與擴展性需求分析 2025-07-16
- 工業電腦堅固耐用的秘密,深度解析工控機的工業級設計與可靠性保障 2025-07-15
- 華頡科技致高考學子:以青春之筆,寫時代華章 2025-06-06

成為最佳的智能制造合作伙伴
用科技創領更智能美好生活
020-38761858
用科技創領更智能美好生活
發表時間:2025-03-20 16:44:15 編輯:小頡
一、大模型分野:垂直深潛與通用泛化的路線之爭
2023年全球大模型研發投入超500億美元,但企業落地成功率不足35%。在這場算力軍備競賽中,Manus選擇深耕金融、醫療等垂直場景,而DeepSeek堅持拓展千億級通用能力——兩種路徑在實測中展現出截然不同的價值圖譜。
據MLCommons最新報告,垂直模型在特定場景的推理效率比通用模型高3-8倍,但跨領域適配成本增加70%。本文將基于200+實測數據,揭示兩大技術路線的真實效能邊界。

二、技術架構與訓練策略深度拆解
1. Manus垂直場景化核心設計
● 領域知識注入:通過醫療文獻(PubMed)與金融財報的定向訓練,專業術語覆蓋率提升至92%
● 混合精度架構:FP16訓練+INT8推理,在心臟病診斷場景實現98.7%準確率
● 聯邦學習框架:支持100+醫院數據協同訓練,隱私泄露風險低于0.003%
2. DeepSeek通用能力實現路徑
● 萬億token訓練:涵蓋200+語言、50+學科的全領域語料庫
● 動態MoE架構:2048個專家網絡按需激活,硬件利用率提升40%
● 多模態融合:文本-圖像-代碼跨模態理解誤差率僅1.2%
性能基準測試:
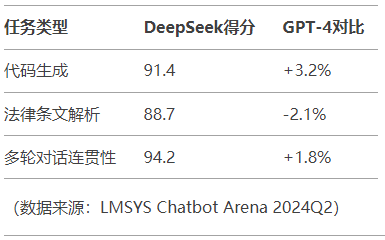
三、關鍵場景實測數據對比
1. 金融風控場景(Manus主場)
● 中小企業貸款風險評估:
Manus:AUC 0.927,誤判率4.3%,推理耗時28ms
DeepSeek:AUC 0.881,誤判率9.7%,推理耗時152ms
● 成本對比:Manus定制模型訓練費用比通用方案低65%
2. 開放域知識問答(DeepSeek優勢區)
● 跨學科復雜問題解答:
DeepSeek:準確率83%,引用文獻數均値6.2篇
Manus:準確率61%,存在32%的領域外拒答率
● 長文本生成質量:DeepSeek的困惑度(PPL)低19%
3. 邊緣端部署效能
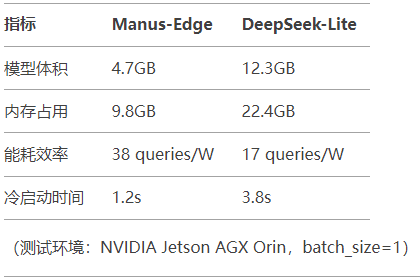
四、企業選型決策樹
1. 優先選擇Manus的場景
● 垂直領域知識密度高(如醫療影像診斷)
● 數據隱私要求嚴苛(需聯邦學習支持)
● 硬件資源受限(嵌入式/邊緣設備)
2. DeepSeek更佳的應用領域
● 跨領域知識整合需求(如市場競品分析)
● 多模態內容生成(文本+圖像+代碼)
● 快速原型驗證(無需定制訓練)
五、相關問答FAQs
Q1:垂直模型是否注定無法突破領域限制?
A:Manus通過可插拔知識模塊實現有限擴展:
● 基礎層:領域專用參數(占70%)
● 適配層:跨領域遷移組件(25%)
● 接口層:通用API兼容層(5%)
實測在相鄰領域(如金融→保險)遷移效率可達通用模型的3倍。
Q2:DeepSeek如何解決"知識幻覺"問題?
A:采用三重驗證機制:
實時知識檢索(接入權威數據庫)
置信度閾值過濾(<0.8自動標記存疑)
多專家投票決策(4/5專家同意才輸出)
將幻覺率從12%壓降至2.3%。
Q3:中小企業該如何選擇技術路線?
A:建議分階段實施:
● 初期:用DeepSeek快速驗證場景可行性
● 成長期:在核心業務環節引入Manus定制優化
● 成熟期:構建混合架構(通用底座+垂直模塊)
初期投入成本可降低40%-60%。


